
有了自知之明才能做對的事情,得益於老客户的信賴和我們過去幾年實踐經驗的積累,今天終於算是完成了一個大型任務。
前幾天我們的客户遇到了一個大問題,因為具體細節有關隱私和安全防護,就不多介紹,主要是去年到今年我們給部署了五台 WordPress 多站點站羣服務器的老客户突然全部網站系統發生異常,訪問慢或者 502 錯誤、後台打不開,原因是這幾台服務器都共用的一台 RDS 數據庫服務器 (阿里雲),也就是客户開啓和創建的子站太多,每台機器差不多有 1~2000 個站,而且都是活動和動態更新的網站。
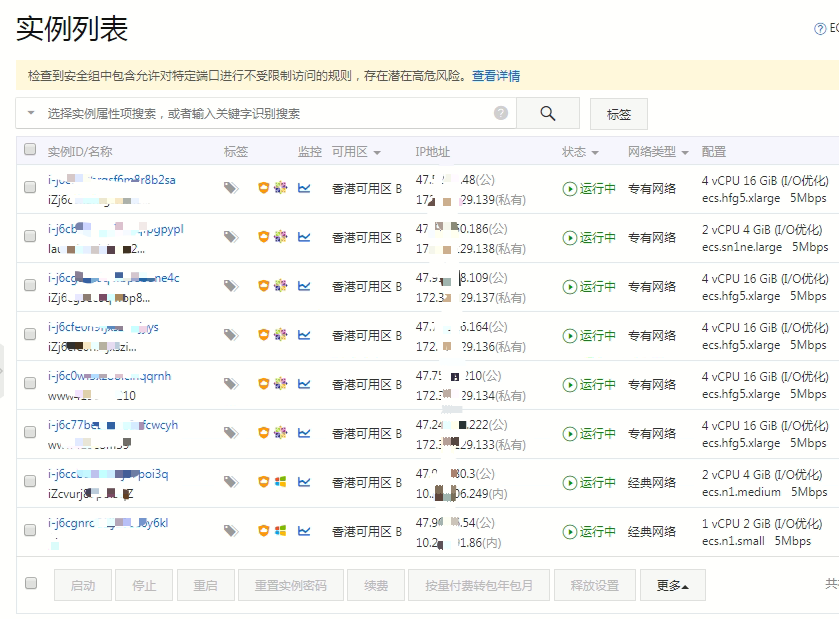
突然就出現了服務器無法正常訪問或者很慢間歇性的故障,檢查了下 RDS 數據庫用量,發現純數據庫的大小已經超過了 100 多 GB ,而且 CPU 已經是 97% 以上,快要爆表了。
要解決此問題有兩種方式,一種是升級阿里雲的 RDS 數據庫提高性能,另一種就是新購一台數據庫服務器,然後將五個 WordPress 多站點站羣的數據庫給切割分離,這些操作並不是最麻煩的,真正的麻煩是阿里雲對數據庫做了一大堆的限制,連正常的數據表導出都沒辦法實現,每次只能導出 100 張表,但現在數據庫裏面有超過 8 萬張數據表。
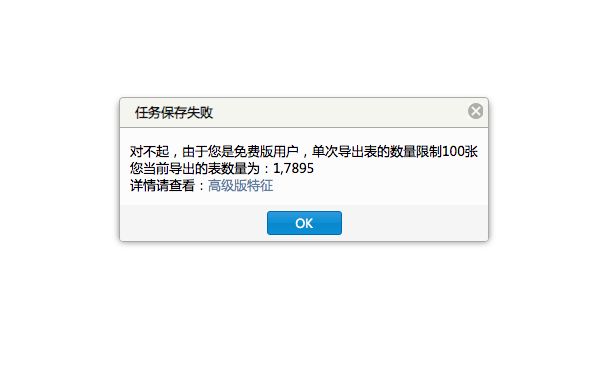
看了下阿里雲的 RDS 企業版説明,升級後最多可以一次導出 10GB 的數據,這樣的話也是很雞肋,因為五個 WordPress 系統的數據庫加起來是 100 多 GB ,這樣的話即使一次導出 10 GB,也都得十次才能導出完,另外導出後還需要下載,再次上傳。。。這麼操作起來,起碼得一週左右的時間跨度才能把這些數據處理完。
花了一個早上,我們制定了一個方案,確切的説是換了種思路,還是想辦法從 WordPress 系統本身也就是 Web 程序端入手。
既然阿里雲限制不允許進行大批量的操作,那麼換種方式,我們直接從 WordPress 站羣系統裏先 「導出」 一個包含全部子站數據庫表的完整備份不就行了。這樣的話,我們只需遷移的舊服務器的數據庫備份,然後再去新數據庫裏恢復。
操作步驟也公佈下:
1 、進入 WordPress 多站點站羣,導出全部子站的數據庫,保留好備份 (A),再對全站的靜態數據和系統文件進行備份;
2 、調配好新的數據庫,然後刪掉/修改 WordPress 多站點站羣的配置文件,再用新庫 (B) 的信息進行安裝,也就是程序再全新部署一次;
3 、將備份數據庫文件進行恢復處理,這樣就可將舊站 (A) 的數據全部都恢復到新的數據庫 (B),而且保留了原始文件和網站結構;
上面的三個步驟看上去很簡單,但對於一個單就數據庫超過 100 GB 的項目來説,並不容易,因為本身系統的資源就已經不夠了,我們採取的策略是備份某一台服務器數據庫的時候先對其他幾台進行停機處理。
舊庫備份成功後,再到新庫 (B) 裏面創建一個信息與舊庫 (A) 一樣的數據庫,然後手動將站羣程序再使用新的數據庫信息部署一遍,這樣就不再使用舊庫 (A) 裏面的數據表,但新庫 (B) 裏面目前還是空白的,後面通過 Web 端的 WordPress 程序恢復原先備份的舊庫 (A),等待數據導入完成後,也就遷移搬家完成了。
經過反覆測試了整整三天的時間 (白天晚上都在試),我們完成了對數據庫的分離和遷移,也就是將其中的三台 WordPress 站羣服務器給遷到了新庫中,整體的數據量加起來差不多有 3000 多個站點,而原先的舊數據庫也得以減負了幾十 GB ,現在各個站點都已經恢復正常可用。
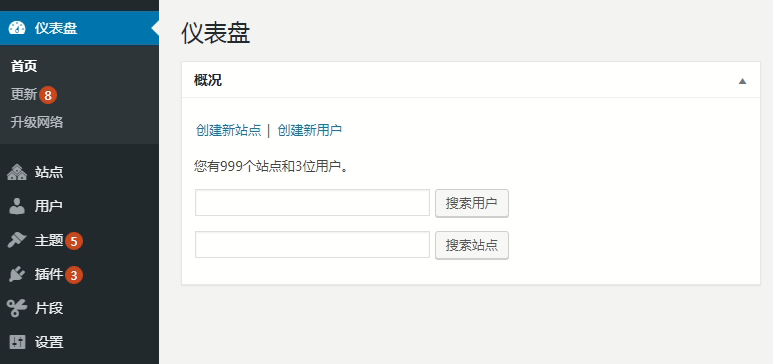
這是我們做的最大規模的一次數據遷移和數據庫分離,五台服務器全部的子站加起來有 5000 多個 WordPress 站點,然後分離後成功遷移差不多 3000 多個 WordPress 站點。
除了我們對站羣系統的性能優化外,WordPress 系統本身良好的數據結構和可擴展性也是不可忽視的因素。
總體來説,這個數據遷移訂單處理的沒那麼輕鬆,但也不是很棘手,更重要的應該是此次的折騰操作讓薇曉朵具備了處理 TB 級別 WordPress 大數據的能力 (1TB=1024GB),也對大型數據庫的處理有了更深入瞭解。
同時這也為我們後續的 WordPress 多集羣和多租户系統解決方案有了一次測試和實踐的機會,未來我們想在一天之內就可以轉移和遷移 10000 個 WordPress 網站,雖然現在一般站羣客户都是隻有開 2000~3000 個站的,但越往後發展,我們可以做和能做的事就會越多。